
Buy vs. Build: The Case for Purpose-Built AI in Consumer Intelligence

Introduction
As AI capabilities become more accessible, a natural question arises inside many organizations: could we build this ourselves? It is a legitimate question, and one worth examining carefully. This document presents the key arguments for why purchasing a purpose-built AI platform consistently delivers more value, faster, at lower total cost, and with significantly less organizational risk than building an equivalent capability in-house.
What follows is a set of considerations that organizations consistently encounter when making this decision drawn from industry experience, customer patterns, and the evolving realities of building with AI at scale. They are intended not as a verdict, but as a framework for having a more complete conversation.
1. Product Catalog Intelligence Takes Years to Get Right
Building a reliable product catalog sounds straightforward until you are in it. The same product can have different names across different retailers, can appear as duplicate listings on the same platform, and can have meaningful variants inside a single parent SKU that need to be broken out. A general-purpose AI queried ad-hoc will miss URLs, conflate variants, and return incomplete results because it has no persistent, curated catalog to draw from.
Specialized platforms have spent years solving this problem in a specific industry context: using computer vision to map products from images, AI-assisted naming conventions, and optimized human-in-the-loop workflows to get to 95%+ accuracy. That depth of institutional knowledge is not something that can be replicated quickly with a development sprint.

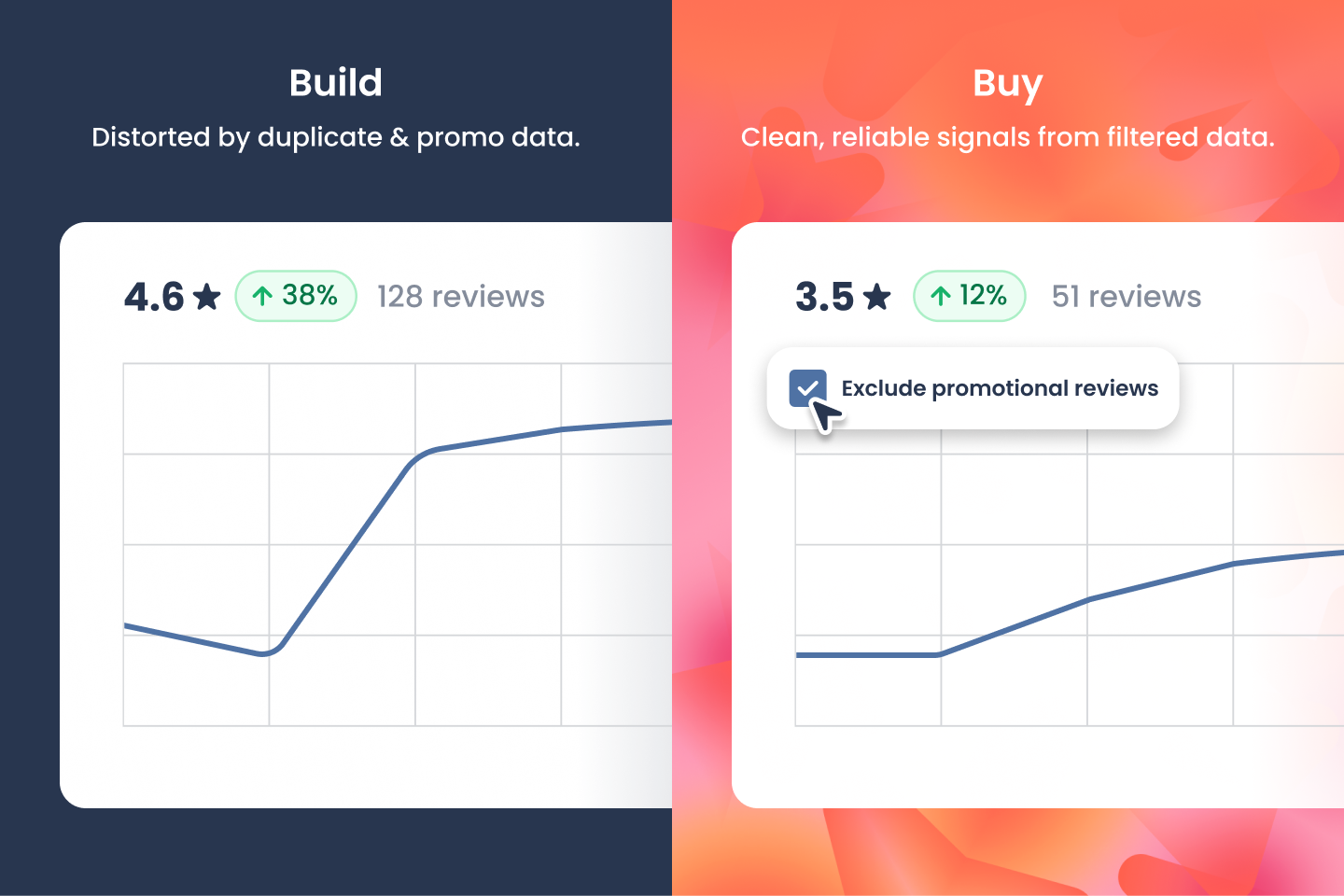
2. Data Quality Is Non-Trivial - and the Errors Are Silent
Syndicated reviews can lead to the same consumer review republished across multiple retailer sites. If not detected and removed this will inflate a data set and distort conclusions. A one-off product complaint can look like a systemic crisis. Similarly, promotional reviews skew sentiment upward and potentially hide product issues. They need to be marked accordingly so analysts can include or exclude them as needed.
These are data hygiene problems that typically only surface after the analysis is already wrong. Purpose-built platforms treat deduplication and review classification as core infrastructure - not as an afterthought.
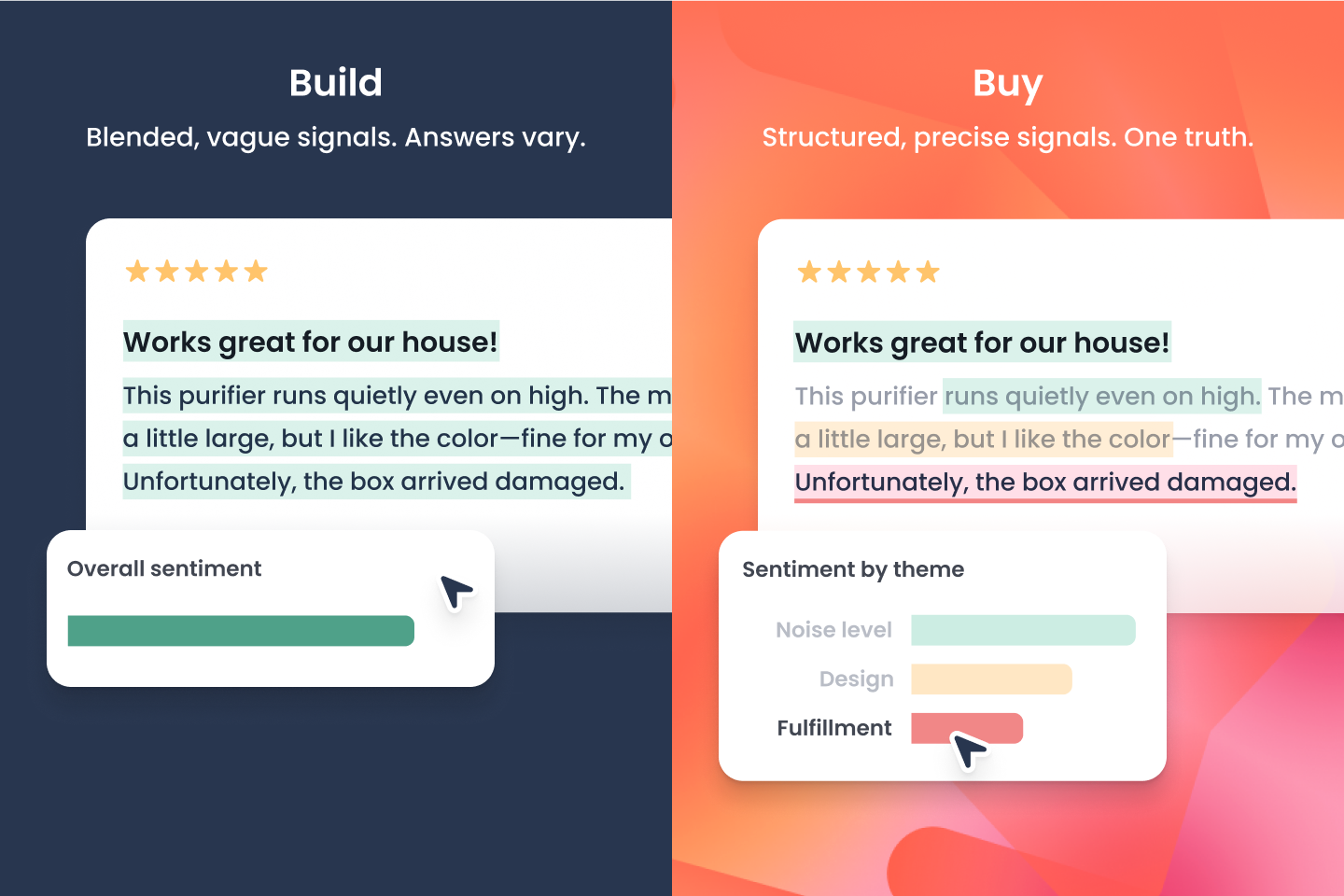
3. Every User Should Get the Same Answer
Ask a general-purpose language model a question today and you get one summary. Ask the same question tomorrow and you may get a different one. Across a team, this creates competing versions of the truth, and because the differences are subtle, they often go unnoticed until they matter.
Platforms that assign themes and sentiment at the sentence level and store those results in a structured database solve this at the foundation. Every user draws from the same source, and any finding can be traced back to the exact reviews that produced it. That makes the analysis auditable in a way a generated summary never can be.
The quality of the classification matters too. Purpose-built models, benchmarked regularly against human-labeled data, ensure that theme and sentiment assignments are consistent and defensible, not the output of a generic model applied ad-hoc. That is what separates a real analytical system from a prompt.
4. The True Cost of Building Is Almost Always Underestimated
The business case for building internally tends to focus on headline engineering costs and systematically underestimates everything else: model infrastructure, data pipeline maintenance, security reviews, compliance requirements, ongoing model upgrades as the AI landscape shifts, and the opportunity cost of pulling senior technical talent away from core business problems.
Internal builds also rarely benefit from economies of scale. Every cost is absorbed by a single team. Specialized platforms distribute R&D investment across their entire client base, meaning customers benefit from far more innovation per dollar spent.

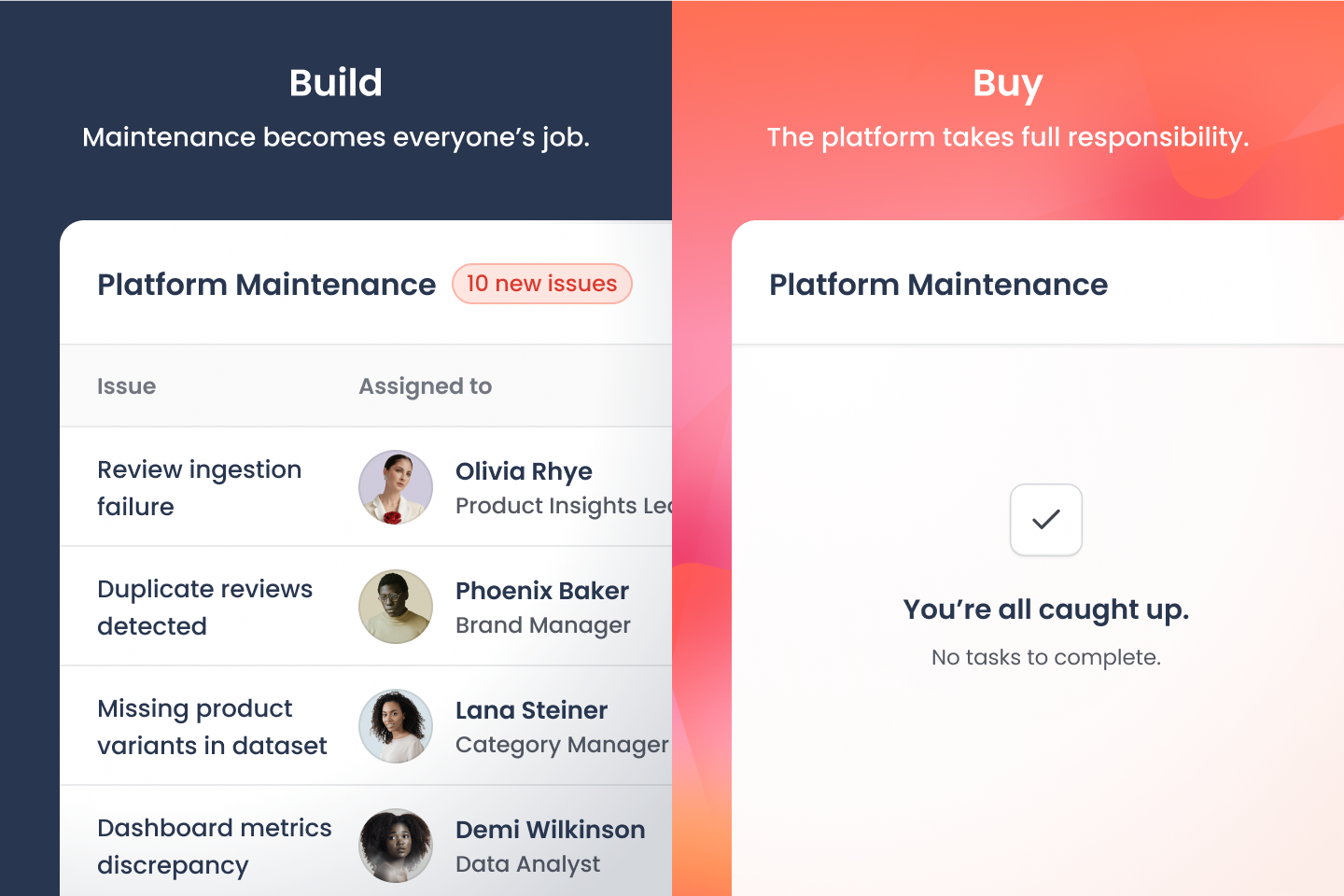
5. Every Tool Needs an Owner — Who Is It?
The build decision tends to get the most attention; what it takes to maintain a tool rarely does. Data sources change formats, models drift, and things break in ways no one anticipated — and someone has to deal with all of it, consistently, over time.
That someone is rarely obvious. Brand managers, insights leads, and category teams are not hired to manage data pipelines or troubleshoot model outputs, yet the work finds its way to them when there is no clear owner. Hiring a dedicated person is hard to justify, and sponsoring headcount in a partner team means competing for time against other priorities. In practice, the team that built the tool moves on, and maintenance quietly falls into a gap. Purpose-built platforms absorb that responsibility entirely.
6. Keeping Up with AI Model Evolution Is a Full-Time Job
The model that powers an internal build today will likely need to be replaced or significantly rearchitected within 6 to 12 months as better foundation models emerge. Specialized vendors dedicate their entire R&D budget to tracking that frontier: incorporating new models, new modalities, and new agent capabilities - without disrupting clients. For most organizations, maintaining that pace internally is a distraction from their primary business.

7. Speed to Value Is a Real Competitive Variable
A production-grade AI system typically takes 12 to 18 months to build. Purpose-built platforms go live in weeks. In markets where consumer sentiment shifts quickly and competitive windows are short, the time spent building rather than learning is a tangible cost.

8. Cross-Client Learning Creates a Compounding Advantage
Platforms that operate across dozens of clients encounter edge cases, data anomalies, and industry-specific nuances at a scale no single organization can match. Every problem solved for one customer improves the platform for all of them. An internal build learns only from its own data and team experience. Over time, the gap between a platform refined across an industry and a single-organization internal tool widens - not narrows.

The Bigger Picture: Where Does This Land on the AI Maturity Curve?
The company Notion created this helpful mental model that shows how to go from manual, fragmented work to AI-powered operations.
This is perhaps the most important consideration of all. A general-purpose AI that summarizes consumer feedback on demand represents Level 1 maturity: AI as a Thought Partner. It answers today's question, with today's model, once.
The organizations that will lead in the next three to five years are those advancing toward Level 3 and Level 4: AI operating as Teammates and as the System that is running autonomously in the background, surfacing issues before teams know to ask, and taking meaningful work off human plates entirely.
Purpose-built platforms are already operating at Level 3. Internal builds, scoped and staffed by teams with primary responsibilities elsewhere, mostly produce Level 1 tools, sometimes Level 2.
The question worth asking is not only "Can we build this?" but "Where do we want to be in three years and what is the most direct path to get there?"
What It Takes to Build Yogi Internally
To build a system similar to Yogi, an internal team would need to develop and maintain a set of interconnected capabilities that extend beyond applying a single AI model. At a high level, this typically includes:
- A product–retailer URL discovery layer that can generate and maintain a comprehensive set of product URLs across retailers, despite differences in naming, duplication, and frequent page changes
- A review collection layer, including scrapers and supporting infrastructure, to gather data across multiple retailer sites and adapt as those sites evolve
- A product catalog and entity resolution system to map reviews to the correct products, manage variants, and maintain a consistent structure over time
- A feedback ingestion and normalization pipeline to standardize review data across formats, languages, and metadata differences
- Deduplication and review quality processes to identify syndicated content, flag promotional reviews, and ensure a reliable underlying dataset
- A theme and sentiment classification system that converts unstructured text into structured insights, with ongoing evaluation to maintain consistency and accuracy
- A user interface designed for analysts and business users, enabling efficient exploration of data, drill-down into source reviews, and consistent outputs across teams
- A monitoring and insight layer that helps surface trends and emerging issues, either through automated alerts or assisted analysis
Each of these components can be built internally, but they typically require ongoing iteration and maintenance as data sources change and AI capabilities evolve. As a result, organizations considering this path often evaluate not just the initial build, but the longer-term effort required to operate and improve the system over time.
Unified Intelligence, Finally Within Reach
Ask Yogi cuts through silos and transforms scattered feedback into one continuous thread of truth—accessible to every team, whenever they need it.
It’s fast, defensible, and finally, actionable.
If you’ve ever wished for a way to get to the “why” behind your data without the delay—it’s here.
For a limited time, book a demo—and ask Yogi anything.
.png)

